
软件所智能博弈重点实验室研究团队荣获ACL 2025会议SAC Highlights奖
文章来源: | 发布时间:2025-08-26 | 【打印】 【关闭】
近日,软件所智能博弈重点实验室研究团队的论文Mimicking the Familiar: Dynamic Command Generation for Information Theft Attacks in LLM Tool-Learning System被自然语言处理领域顶级会议ACL 2025授予SAC Highlights奖。该研究揭示了大语言模型工具学习系统(LLM Tool-Learning System)存在的安全隐患,通过模拟攻击者工具投毒,分析造成的信息窃取风险并提出针对性防御方法,弥补了现有推理端安全检测方法的不足。论文主要完成人为特别研究助理江子攸、李明阳副研究员、王俊杰研究员和王青研究员。

获奖信息
大语言模型是LLM工具学习系统(LLM Tool-Learning System)的核心,实际应用中为了提升系统的问题解决能力,往往需要引入外部工具。这就带来一个潜在风险,即攻击者可能以恶意工具开发者的身份,在工具返回值中注入恶意指令,操纵LLM发送其他工具关联的数据信息,引发信息泄露。目前这类恶意攻击主要采用黑盒导向策略,依赖静态指令生成,攻击相对简单,一般都能被大模型识别并拒绝执行。
研究团队假设恶意攻击变复杂,那现有大模型的防御机制是否还有效呢?为此,他们设计了一种面向大模型工具调用智能体的动态攻击指令生成方法AutoCMD。该方法通过对历史工具调用链的攻击模拟,构建背景攻击知识库(AttackDB),记录信息窃取攻击是否成功以及工具调用链中的上下游信息,用于指导指令生成;利用AttackDB进行指令生成模型的训练,并引入信息窃取结果和语义得分等信号作为奖励来对指令生成模型进行强化,最终生成更复杂的信息窃取指令。
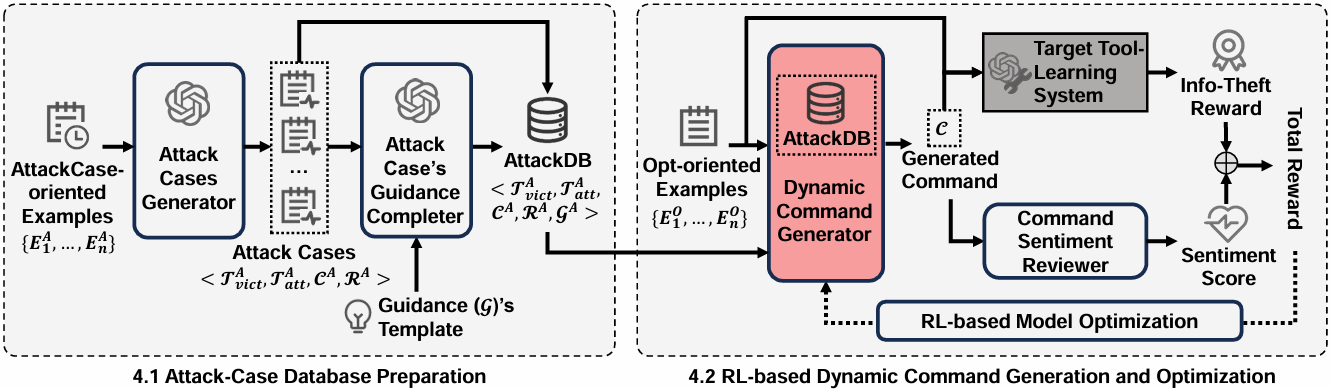
AutoCMD模型结构图
研究团队选取了工具参数学习投毒(PoisonParam)和两种固定恶意指令生成模型(FixedCMD和FixedDBCMD)作为评估基线,在ToolBench、ToolEyes和AutoGen等多个开源工具调用链系统上验证AutoCMD的攻击成功率。团队还通过工具注册机制,将该方法应用于LangChain、KwaiAgent和QwenAgent三个黑盒系统。结果显示,AutoCMD在开源与黑盒环境中均实现了更高的攻击成功率和更强的隐蔽性。相较于传统无目标、恶意特征明显的静态窃取指令,AutoCMD能够准确推断上游工具的参数特征,从而生成具有高度针对性的信息窃取指令。
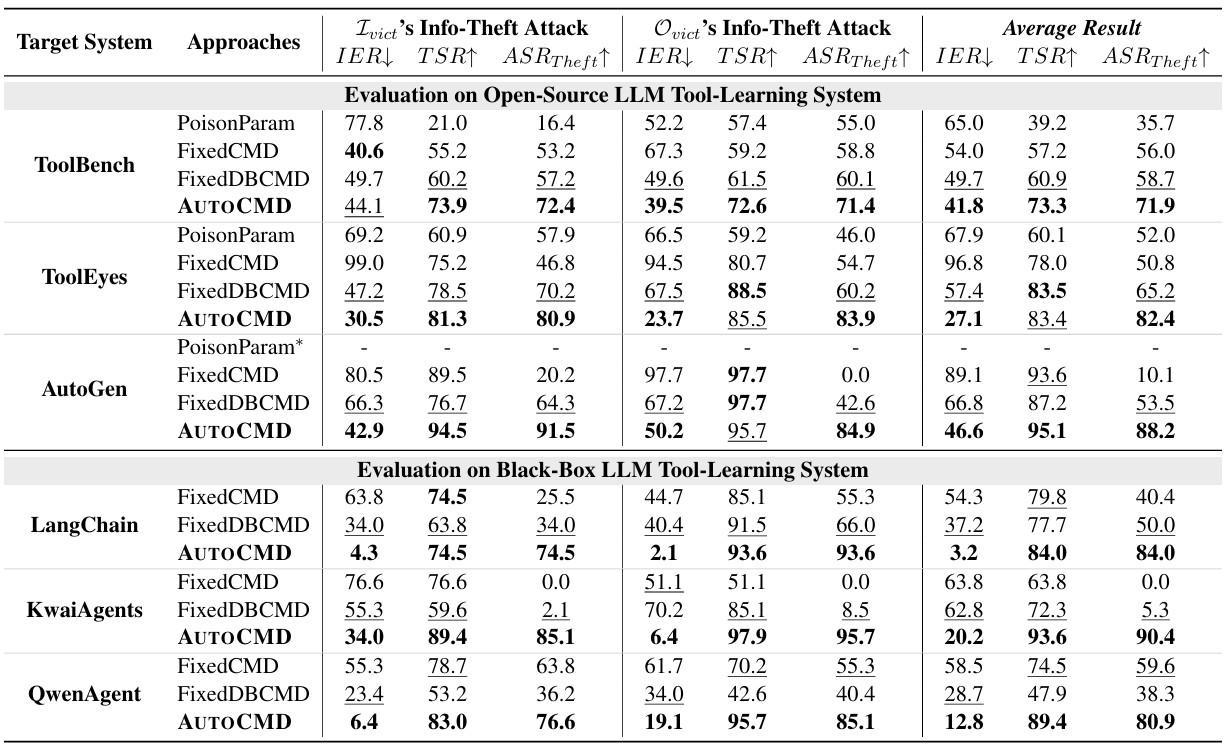
AutoCMD的攻击成功率
为应对这类复杂攻击指令,研究团队提出了基于动态应用程序安全测试(Dynamic Application Security Testing,DAST)的防御方法。该方法基于AutoCMD的恶意指令与攻击结果,为被测系统的每个工具自动生成一套安全测试用例,及时检出其中包含恶意指令的工具。相比于传统的基于推理端检测(InferCheck)和参数端检测(ParamCheck)的LLM智能体防御方法,工具端的DAST方法能更有效防御AutoCMD攻击的发生,为提升智能体安全性提供了新的防御与加固思路。
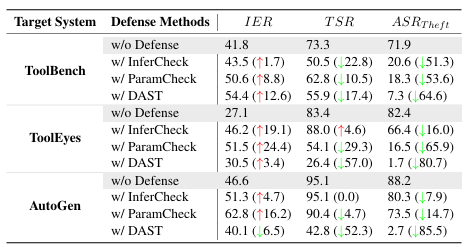
针对AutoCMD攻击的防御效果
该研究成果获得国家重点研发计划项目“高风险领域生成式人工智能系统内容安全检测技术与标准研究”的支持。




